Process and serve millions of images and videos efficiently - A media management system for social networks


Media files have become indispensable for all Web/Mobile/TV applications in today's digital-first world. Any online business such as E-commerce, EduTech, News and Media, Social Media, Dating, Online Food and grocery apps, and Hotel booking is immersive, captivating and addictive because of the media content such as Images, Videos, Audio, Live streams, etc.
Developers often approach media management as a part of a specific feature or service. Code for handling the media files like upload, fetch, edit, delete, cleanup, etc, is usually tightly coupled with the specific functionality even though these media files' underlying storage and delivery mechanism are essentially the same (cloud file storage solutions like Amazon S3 and CDN solutions for delivery). But what if I told you there is a better solution for your media management needs?
A solution that you can build once and use anywhere and anytime.
I have been building SaaS applications and social media platforms for a long time. The engineering complexity of handling media in these categories of platforms is a fascinating problem statement for two reasons -
-
There is no limit on the functionality you need to build. These platforms typically have a wide variety of functionalities for serving the needs of different types of users, and many involve handling and serving media files.
-
There is tons of user-generated content, and it's tough to reliably calculate how much media content a single user will consume or generate.
Let me take the example of basic functionalities in Instagram to give you a high-level idea of how media files are used across various functionalities -
-
Your profile contains your profile picture.
-
A single post can contain multiple photos or even videos.
-
A story post can contain audio files and images.
-
Reels contain video files.
-
DMs can have images/videos/audio, and much more.
Instagram is a social network built around images and videos, so you may consider it an exception. But think about any typical online first business like E-commerce, Food delivery, ride-hailing, financial transactions or anything else. Most of them have profiles that contain media, products/offerings that contain media, etc.
Apart from this, media files have their own specialized set of requirements, such as -
-
Compressing the files - Each media file type(video, images, audio) has a different compression need(usually different methodology).
-
Creating different variants of the image files - Think of thumbnails and different sizes of the same post for optimized viewing on different devices and networks.
-
Breaking down large video files into chunks for video streaming. (See HLS)
-
Keeping track of metadata such as file sizes, extensions, etc.
-
Keeping track of the file storage system used and the CDN provider used - I know most people use only one, but keeping track in case you need to change the vendor for any reason in the long run.
I have used a generic media management system for the last ten years, which has seen huge success in availability, reliability, manageability and extensibility in different use cases. It's also loved by developers in my teams because once programmed and stabilized, it's effortless to use it in new functionality or even make changes to the old functionalities.
In this post, I will give you a high-level idea of how to build a similar system for your organization. But first, let's look at the product requirements from an engineering perspective.
I will take Instagram as an example (wherever required) because it's highly relatable for most people. From an engineering perspective, we have to solve the following problems.
-
Maintain a mapping of media storage structure in our database - This system is supposed to act as a generic media management system for all the media needs of the platform in the present and future. It should be able to track the individual media files associated with different entities (posts, stories, profile pictures) and store this association in a database.
-
Store the information associated with the media files - The database entries should also track the file types, file extension, file size, creation and updation timestamps, CDN endpoints, relative URL, user identifier, entity Identifiers, soft and hard delete status, etc.
-
Ability to map multiple media providers - we must keep a unique key to map the media provider (Amazon S3, Google Cloud Storage, Cloudflare, etc.) in the database. This will help us use multiple vendors, and we can switch based on the cost consideration whenever and wherever (for a particular feature) we want.
-
Ability to generate signed URLs based on media providers for media access- We will write separate utility functions for each media provider to perform various functions like redirects, generating signed URLs, etc.
-
Maintain a cache of signed URLs - Each Signed URL generated by the system will have X hours (or minutes) of validity. This will help us speed up media access using signed URLs, and we'll not need to generate a signed URL for each file access request.
-
Generic file upload interface - The sytem should have a generic API/GraphQL (replace with whatever you are using) endpoint for file upload that is unaware of the folder structure and other storage requirements for each entity type and its variants. In our file storage service, we will keep a neatly organised folder structure for storing and mapping media files.
-
Cleanup of signed URLs that were not used - We need to track when a signed URL was generated, but the media file was not uploaded using that URL. This will help us perform cleanups on our media database.
-
Cleanup of files whose entities have been deleted - The system should be able to delete the files whose associated entities (post, comment, message, status, etc) have been deleted.
A few important side notes before you move forward -
-
File extensions and File types should be standardized in your system. Don't keep the original file extension uploaded by the user. I recommend changing the media file to a standard extension according to the media type. This will give you a huge boost in client-side caching and rendering speed and help you in compression and storage optimization. Choose the format(extension) that supports your use case based on factors like what kind of network your users typically have (wifi/4G/5G), whether it's a mobile app or web app, what is the access pattern of the media for a typical user and how much media you have to render on a single screen or scroll.
-
If you don't know what Pre-Signed URLs are and what are the advantages of using them, you should read up on them. In Short - they are a secure way to upload files directly from your client to your storage solutions like Amazon S3. This upload is very fast because it doesn't need to go through your server-side application. Similar URLs are also used in file delivery to ensure your media files are secure.
-
If you don't know what Content delivery networks are, please read up on it.
-
Media processing is a CPU-intensive activity and should be performed asynchronously. (I have explained this later)
-
While maintaining the cache of Signed URLs, keep your end user behaviour and feature behaviour in mind. For example, if you are posting a story on Instagram, then you cannot change the media associated with the story, and also the stories are live only for 24 hours. So, your cache settings should be optimized for this.
Solution - High-level working of the media management system
The following diagram explains the high-level working of the system and all the components used.
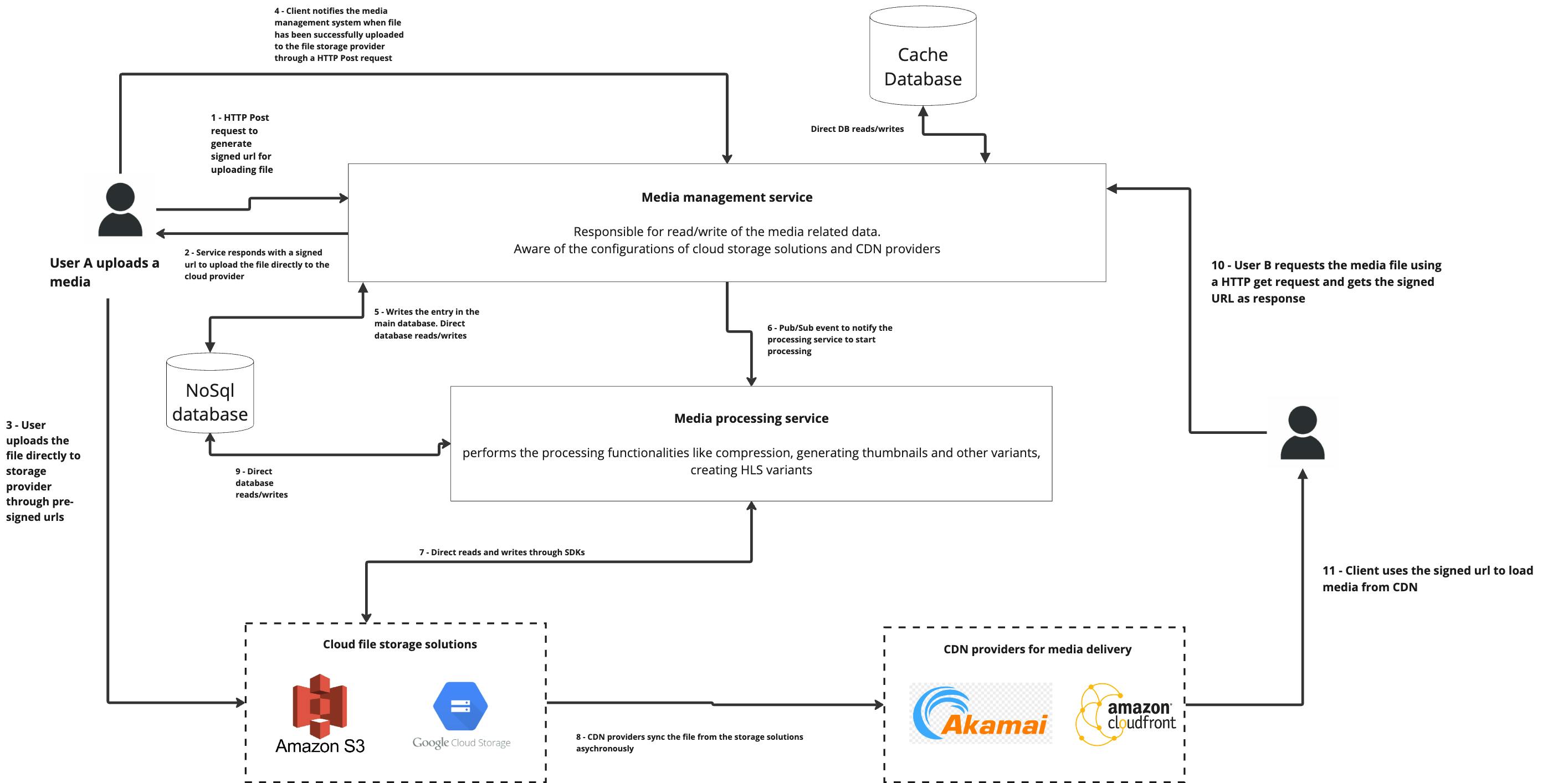
Following is how the system works -
-
There are two services in the system. One is responsible for the CRUD operations related to the media files, called "Media management service", and another is responsible for all the processing and cleanup activities called "Media processing service".
-
When a user wants to upload a file for any entity (post, status, message, etc.), the client application (web/mobile) fires an HTTP request to generate a secure Pre-signed URL for upload. The media management service performs all the necessary validation and authorization checks based on the data (user's unique ID, entity ID, rate limiting, etc) and generates a Pre-signed URL for upload. The Logic of this API endpoint for generating the signed URLs is aware of the base folder structure for the entity through a configuration file. The Client passes the required input parameters(entityId, entityType, variant name, etc.) and, in return, gets a signed URL, which can be used by the client to upload the file to the storage provider directly.
-
The client uploads the file directly into the cloud file storage solutions (Amazon S3, Google Cloud storage, etc) using the secure Pre-signed URL. Since this upload is not going through our backend services, the client has to notify the media management service once the upload is finished. It passed the final file information received from the file storage solution in another HTTP request to the media management service.
-
Once the file upload is confirmed, the media management service triggers a pub/sub event to notify the Media processing service. Upon receiving this event, the processing service starts processing according to the media type and the business logic for handling this file. It concurrently starts all the processing, like compression, thumbnail generation, image variant generation, HLS generation, etc. Please note that only the media processing service is aware of how each file should be treated, what processing has to be done and where and how to store the resultant files from the processing activity. Custom functions are written based on your organisation's product and business requirements for achieving this. Also, Media processing is usually both CPU and memory-intensive. So, the service should be deployed and monitored with these requirements in mind.
-
When another user requests this file while consuming the content (post, message, story, etc.), it has only one piece of information - The unique identifier of the media object (
mediaId) with it. I will cover why I have kept it this way in the low-level design (covered later in this post). So, all the entities (post, comment, story, messages) store only themediaId(s)in the schema, and they are unaware of any other details of the media file. This de-coupling makes this system generic, and most of the magic lies in the system's low-level design, which we will cover later. -
So, the client makes the HTTP GET request to the Media management service using the
mediaId(the unique identifier of the media) and also passes any other relevant information using query parameters. For example, in the case of Instagram, your profile picture can have multiple variants, like small, medium, or large, depending on where they are displayed in the app. If it is on the profile page, it's a medium-sized image. But if you are looking at the same image in the comments section or messages, it's a small-size variant. In case you don't know this, it's a prevalent practice to ensure the end-user experience is excellent in loading the media files, and it also saves tons of bandwidth costs on the company's end. So, in this case, a query would look something likeGET <base url>/fetchMedia?variant=small.You can pass multiple query parameters as well. -
When this request to fetch a media file reaches the media management service, it performs the necessary validation, authorization and other security checks, and instead of responding with a JSON response, it directly does a 301 redirect to the URL of the media file stored in the CDN. Now, please beware that depending on the media processing speed of your system (Which is essentially a factor of how well the code is written, the infra-provisioned, and the concurrency handled by that service); there is a slight chance that the variant client requested was not available at the time of requests. In that case, the media management service should have logic in place to redirect to the original file. As you can imagine, numerous conditional statements would have to be written in the logic of this endpoint. These conditions depend on the type of media file requested and your corresponding CDN setup. So, it will first perform a lookup in some NoSQL DB to fetch the detailed record of the media using the
mediaIdand then execute the corresponding checks before the final redirect. But that's also an easy check because of the low-level design of the system (Discussed later). -
Another vital point to note is the synchronization of files between your media storage solution and your CDN provider. In most cases, it's supported automatically (for example, AWS S3 and Cloudfront), but if you are using a provider that doesn't support your storage solution, you must write the code for it in the Media processing service. You can leverage the same pub-sub event and add this as another activity.
-
To ensure that the
fetchMediaendpoint is extremely fast - you must cache the Pre-signed URL from the CDN provider. Also, be cautious about the expiration you set for your pre-signed URL and the cache. It should be decided based on factors such as your security needs, end-user access patterns, availability of correct file variants, etc. Also, please store the signed URL in the cache instead of the entire media object. This will ensure that your redirects are fast and you are not wasting storage. So, it's a simple key-value storage in the cache database. -
Your cleanup tasks should happen asynchronously in the media processing service, such as deleting lingering file entries that were not uploaded correctly and cleaning up media entries for deleted entities. You can use any cron-like scheduler for the cleanup tasks, and then it will just call a function that finds these entries in the table using database queries and performs necessary updates.
Now that you have an Idea about how this system works let's discuss the low-level design of this system.
Low-level design and the reasoning for it
This system requires you to have only one table/collection called MediaInformation.
// Schema
// Table Name - MediaInformation
mediaId - string - a unique identifier for this entry - 20 chars
userId - string - unique identifier of the user who upload the media file in the system - 20 chars
fileName - string - 20-25 characters
createdOn - number - epcoh timestamp in milliseconds
lastModifiedOn - number - epoch timestamp in milliseconds
entityId - string - upto 50 characters - unique identifier of the entity which this media is related - example are post/message/story/comment
entityType - string - upto 50 characters - type of the entity which this media is related - example are post/message/story/comment
variantName - string - which variant is this entry - example - original/compressed/thumbnailSmall/thumbnailLarge etc
mediaIdVariantIndex - string - a field that combines the variant and id into a single string for indexing purposes
storageRelativePath - string - upto 100 characters
storageProvider - string - example values are AmazonS3 and CloudFlare
cdnRelativePath - string - upto 100 characters.
cdnProvider - string - example values are CloudFront and CloudFlare
mediaType - string - example values are image/audio/video
mediaSize - number - in Kbs
fileExtension - string - example values are jpg/jpeg/png/mp4/mp3/wav
mediaStatus - string - example values are signedUrlGenerated, live, unpublished
Most fields in the above schema are self-explanatory. So, let's discuss the ones that aren't -
-
entityId and entityType - I mentioned this several times in this blog post. The point of the system is to be generic. So, every type of media you store can be called an entity, and it will have an
entityTypeandentityId(unique identifier). In the Media management service and Media processing service, we have to store all the possible values ofentityTypesin the form of a configuration file. All the processing functionality will also be tied to whatentityTypewe are processing. For example, in the case of Instagram, you can haveentityTypessuch asprofilePicture,postPicture,postVideo,postAudio,storyPicture,storyVideo,messagePicture,messageVideoetc., and theentityIdwill be the unique identifier from the corresponding tables of these entities. For example, for a video in a post, theentityTypewill bepostVideoandentityIdwill be thepostId(unique ID in a table called post). -
Variant name - This field stores whether this media entry is the original file uploaded by the user or a processed version. Again, both the media services (management and processing) have to keep track of all the possible variant values for a particular entity type. This depends entirely on your use case and the different screens where this media is rendered. For example, OTT platforms must generate several variants of the same media file for a better rendering experience on different devices.
-
mediaIdVariantIndex - This is the hack I have used in several systems. Understand your end user access pattern. For each media, in 99% of the cases, the client will pass the
mediaIdand the variant name. So, by introducing an additional string field, which is nothing but a concatenation of the values stored in themediaIdfield andvariantNamefield, you can create a global Index on your table to speed up the query. I know many modern databases have come up with compound indexes based on two fields built into the database engine, but in a distributed database environment, a simple index will always give you a better performance(for example - less than five milliseconds of read latency). Also, this index will allow you to check whether a specific variant for a media file is available or not using a single database lookup (I mentioned this in the previous section - point 7 of how this system works). -
Relative paths for storage and CDN provider - If you are still storing absolute paths, please don't. There is no upside and several downsides!
-
Name of the media provider and CDN provider - These fields ensure the system is generic. Your organization can have file storage and delivery distributed across the globe, and you may need different providers in different regions for several reasons like cost, operational ease, availability of edge locations, etc. When the
fetchMediaendpoint is called, it will take the Base URL of the file based on the media provider and the CDN provider. These Base URLs should be stored in a simple configuration file for speed. -
File information fields - I have only mentioned two fields for file metadata. But in real-life production environments, you must store much more information according to the media type. For example, in the case of video/audio, you may need to store the FPS(Frame per second). In the case of Images, you are supposed to store the resolution. Please extend the same schema to include all these additional fields according to your use case. Also, if any of these fields play a pivotal role in the end-user access patterns, then you know what to do -> Create indexes to support faster reads.
A few critical pointers -
-
This system requires the application level to hold many configurations. I know some engineering leaders are fundamentally against this practice and would instead store the configuration in a database to avoid accidentally breaking the system. However, in principle, I don't agree with that approach as it introduces an additional overhead (an extra database lookup), which slows down the system. But if you are one of these leaders, you can use any one of the following suggestions as a middle ground -
-
Keep the configurations at the Infra level and let developers call them using environment variables to avoid accidental manipulation. Build configuration first applications.
-
Set up unit tests and rules in your CI/CD pipelines to avoid bugs arising from the changes in such configuration.
-
-
I have given an example of just one indexing strategy that works in the case of generic systems. But your indexing strategy must match your end user access patterns if you are building media-heavy applications such as social networks, OTT platforms, etc. You may also consider using different tables for mission-critical file types. For example, an OTT platform should store the video data in dedicated tables optimized for delivery.
Tools and technologies used
-
In our case, the services have been written in Go programming language. But you can choose any depending on your scale, developer comfort and cost considerations.
-
We use Google pub/sub for our asynchronous communication because, at our current scale (few lakh total users, thousands of daily active users), it's highly cost-effective. You can use any alternative like Kafka, ZeroMQ, NATS, AWS SQS, etc.
-
Redis - Speed, simplicity and robust data structure. I don't think I need to discuss why redis in 2024.
-
DynamoDB - Again, it is highly scalable and easy to use, and we run it in serverless mode where, despite hundreds of thousands of queries per minute, our total bill is relatively low. It also offers powerful indexing capabilities and single-digit millisecond latency in reads and writes. I would highly recommend using it for this use case. But you can always use any other NoSQL or wide-column database with similar indexing capabilities and speed.
-
Amazon S3 is used for file storage, and Amazon CloudFront is used for content delivery. Again, you can use any other solution. That's kind of the point of this blog post.
Ending note
So, we solved all the problems mentioned in the problem statement section using simple architecture and low-level design magic. I have intentionally not covered a lot of things like -
-
How do you process different types of media files?
-
How do you decide what information to store about each type of media?
Because those are vast topics in themselves and require their blog posts, I am sure I will be covering them soon. This blog post aims to give you an idea about how to do media serving, management and processing effectively at scale. But, if you are going to use this media management system in your organization and want answers to those questions, don't hesitate to get in touch with me. I hope the above system helps you as much as it has helped me. If you have any questions, doubts or suggestions, please contact me on Twitter, Linkedin or Instagram. Do share this article with your friends and colleagues.